本記事は、弊社が提供する「DGX Spark ハンズオン」の演習用副教材であり、座学パートを事前に受講済みであるか、同時に用いることを想定しています。
なお、すべての内容は記事作成時点の資料に基づいており、常に最新の情報が反映されていることを保証するものではありません。
ハンズオンの演習は、次の1~5章の内容から構成されています。
第1章『はじめに』
第2章『DGX Dashboardへのアクセス方法』
第3章『JupyterLab環境について』
第4章『vLLMについて』 ←※本記事
第5章『まとめ』
4. vLLMについて
この章では、LLM推論のための高速推論エンジンであるvLLMについて学びます。コンテナの利用方法や起動手順を通じて、LLM推論を実際に実行するまでの流れに触れています。このセクションで紹介している手順はbuild.nvidia.comの次のプレイブックをもとに作成されています。
Install and Use vLLM for Inference
4.1 vLLMの特徴
vLLMは、LLM向けの推論エンジンを備えたAPIサーバーとして位置づけられます。それら2つの機能に加え、さらに計算リソースの効率的な利用と高速処理を実現するPageAttentionやcontinuous batchingなどの機能を備えています。
4.2 vLLMの起動
vLLMをSpark上で動作させる場合、コンテナを用いるかソースからvLLMをビルドする2通りの方法がありますが、ここではvLLMコンテナイメージを入手しdockerコンテナとして起動させる方法を示します。
・4.2.1 vLLMコンテナイメージのプル
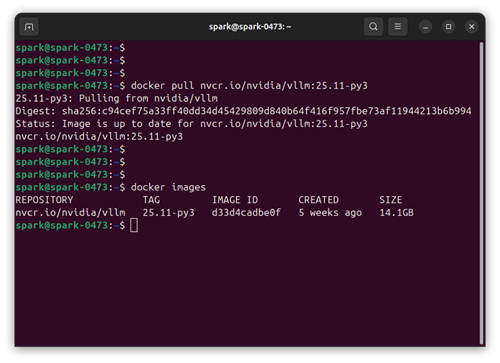
NGCカタログからvLLMのコンテナイメージを入手します。最新のバージョンを確認したい場合、次のリンク先ページを確認してください。
vLLM | NGC Catalog
本ハンズオンを受講している皆様は座学パート冒頭にてすでに本項手順を実施済のことと思われますが、以下にコマンドを再掲します。
docker pull nvcr.io/nvidia/vllm:25.11-py3
コマンドの出力から、Spark上に既にイメージが存在していることがわかります。
・4.2.2 vLLMの起動
ダウンロード済みのイメージからコンテナを起動し、テスト用のモデルを用いてvLLMの基本的な動作を確認します。
docker run -it --gpus all -p 8000:8000 \
nvcr.io/nvidia/vllm:25.11-py3 \
vllm serve "Qwen/Qwen2.5-Math-1.5B-Instruct"
■vLLMコンテナの起動に失敗した場合
JupyterLabインスタンスが起動中である場合、Sparkの空きメモリがひっ迫している可能性があります。インスタンスを停止し、再度上記のコマンドをお試しください。状況が改善しない場合、プレゼンターまでお申し出ください。
コンテナの起動操作後、内部処理の完了まで少々の時間を要します。コンソールに"INFO: Application startup complete."と表示されるまで少々お待ちください。
(APIServer pid=1) INFO: Started server process [1]
(APIServer pid=1) INFO: Waiting for application startup.
(APIServer pid=1) INFO: Application startup complete.
ここでは、中国の Alibaba Cloud が開発した Qwen の軽量モデルを実行しています。Qwen は、大規模から小規模まで多様なパラメータサイズのモデルを揃えており、多用途・多言語に対応できる幅広いラインナップを提供しています。
また、vllm serve以降の記述を変更することで様々なモデルを使用することができるようになります。
4.3 vLLMの動作確認
vLLMの起動が完了した後に、別のターミナルを開き次のコマンドを実行します。
以下の例では、vLLM のエンドポイントに対して 12*17 の計算を実行するようリクエストを送っています。
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-Math-1.5B-Instruct",
"messages": [{"role": "user", "content": "12*17"}],
"max_tokens": 500
}'
このように curl を使って API に直接リクエストを送ることで、アプリケーション側から同様の形式でモデルへ問い合わせが行えるようになります。つまり、このインターフェースを用意すれば、任意のアプリに AI の推論機能を簡単に組み込めるというわけです。
なお、この例で期待される応答は204です。
vLLMコンテナを起動したターミナル:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-Math-1.5B-Instruct",
"messages": [{"role": "user", "content": "12*17"}],
"max_tokens": 500
}'
curlリクエストを投げたターミナル:
$ curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-Math-1.5B-Instruct",
"messages": [{"role": "user", "content": "12*17"}],
"max_tokens": 500
}'
{"id":"chatcmpl-6fe023ebebf44661a8f88cfa37daec5f","object":"chat.completion","created":1765869863,"model":"Qwen/Qwen2.5-Math-1.5B-Instruct","choices":[{"index":0,"message":{"role":"assistant","content":"To solve \\(12 \\times 17\\), we can use the distributive property of multiplication over addition. Here are the steps:\n\n1. Break down 17 into 10 and 7:\n \\[\n 12 \\times 17 = 12 \\times (10 + 7)\n \\]\n\n2. Distribute the 12 to both 10 and 7:\n \\[\n 12 \\times (10 + 7) = 12 \\times 10 + 12 \\times 7\n \\]\n\n3. Calculate \\(12 \\times 10\\):\n \\[\n 12 \\times 10 = 120\n \\]\n\n4. Calculate \\(12 \\times 7\\):\n \\[\n 12 \\times 7 = 84\n \\]\n\n5. Add the two results together:\n \\[\n 120 + 84 = 204\n \\]\n\nSo, the final answer is \\(\\boxed{204}\\).","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning_content":null},"logprobs":null,"finish_reason":"stop","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":33,"total_tokens":269,"completion_tokens":236,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
リクエストを投げたターミナルでは意味解釈や計算過程が表示され、最終的には計算結果の204を得ることができました。
次章の記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
下山 翔也 - Shoya Shimoyama -
NVIDIA社製品のプリセールス・エンジニア業務を担当。
GPUのほか、クラウドサービスやサーバー、ネットワーク機器についても取り扱う。